Publish Date: October 17, 2025
Leading AI Models Excel at Basic Tasks, Lack Scientific Reasoning: Shows Study
Share this on
New benchmark reveals vision language models excel at basic tasks but struggle with complex reasoning essential for autonomous scientific research

In a recent study, researchers from the Indian Institute of Technology Delhi (IIT Delhi) and Friedrich Schiller University Jena (FSU Jena) challenge the current hype around artificial intelligence and large language models in scientific discovery. Their study, published in Nature Computational Science, reveals that while leading AI models show promise in basic scientific tasks, they exhibit fundamental limitations that could pose risks if deployed without proper oversight in research environments.
(Research paper link: https://doi.org/10.1038/s43588-025-00836-3)
The research team, led by Prof. N. M. Anoop Krishnan (IIT Delhi) and Prof. Kevin Maik Jablonka (FSU Jena), developed MaCBench, the first comprehensive benchmark specifically designed to evaluate how vision language models handle real-world chemistry and materials science tasks.
The collaboration was strengthened by Prof. Krishnan’s year-long tenure as a Humboldt fellow at the Chair of Glass Chemistry at Friedrich Schiller University Jena, where the initial discussions and framework for this research began. MaCBench comprises over 1,100 questions spanning the entire scientific workflow, from interpreting research literature to executing experiments and analyzing data. The benchmark tested four leading AI models: Claude 3.5 Sonnet, GPT-4o, Gemini 1.5 Pro, and Llama 3.2 90B Vision across diverse scientific tasks.
The results revealed a striking paradox: while AI models achieved near-perfect performance in basic perception tasks like equipment identification, they struggled significantly with spatial reasoning, cross-modal information synthesis, and multi-step logical inference—capabilities essential for genuine scientific discovery. “Our findings represent a crucial reality check for the scientific community,” said Prof. N. M. Anoop Krishnan. “While these AI systems show remarkable capabilities in routine data processing tasks, they are not yet ready for autonomous scientific reasoning. The strong correlation we observed between model performance and internet data availability suggests these systems may be relying more on pattern matching than genuine scientific understanding.”
One of the most concerning findings emerged from laboratory safety assessments. While models excelled at identifying laboratory equipment with 77% accuracy, they performed poorly when evaluating safety hazards in similar laboratory setups, achieving only 46% accuracy. “This disparity between equipment recognition and safety reasoning is particularly alarming,” explained Dr. Kevin Maik Jablonka. “It suggests that current AI models cannot bridge the gaps in tacit knowledge that are crucial for safe laboratory operations. Scientists must understand these limitations before integrating AI into safety-critical research environments.”
The research team’s innovative approach included extensive ablation studies that isolated specific failure modes. They discovered that models performed substantially better when identical information was presented as text rather than images, indicating incomplete multimodal integration – a fundamental requirement for scientific work.
“What makes our research unique is not just measuring performance, but systematically uncovering why these models fail,” noted Mr. Nawaf Alampara, a PhD scholar under the supervision of Dr. Jablonka at FSU Jena and lead author of the study. “We found that models consistently struggled with tasks requiring multiple reasoning steps, and their performance strongly correlated with how frequently specific information appeared on the internet rather than with actual scientific understanding.”
The study’s implications extend far beyond chemistry and materials science, suggesting broader challenges for AI deployment across scientific disciplines. The research indicates that developing reliable AI scientific assistants will require fundamental advances in training methodologies that emphasize genuine understanding over pattern matching. “Our work provides a roadmap for both the capabilities and limitations of current AI systems in science,” said Mr. Indrajeet Mandal, a PhD scholar under the supervision of Prof. Krishnan at IIT Delhi and an author of the work. “While these models show promise as assistive tools for routine tasks, human oversight remains essential for complex reasoning and safety-critical decisions. The path forward requires better uncertainty quantification and frameworks for effective human-AI collaboration.”
MaCBench has been made freely available to the research community, providing the first standardized framework for evaluating multimodal AI capabilities in scientific contexts. The benchmark’s comprehensive design allows researchers to assess not just performance, but also the underlying reasoning processes. “This benchmark fills a critical gap in our understanding of AI capabilities in science,” emphasized Prof. Krishnan. “By making it openly available, we hope to drive more rigorous evaluation of AI systems before they're deployed in research environments where accuracy and safety are paramount,” added Dr. Jablonka.
The research, a collaboration between IIT Delhi, FSU Jena facilitated by the Humboldt fellowship, highlights the global importance of understanding AI limitations in scientific applications.
The study, titled “Probing the limitations of multimodal language models for chemistry and materials research,” was published in Nature Computational Science and represents one of the most comprehensive evaluations of AI capabilities in scientific reasoning to date. The MaCBench benchmark and evaluation framework are available as open-source resources for the scientific community. The research was supported by the Carl Zeiss Foundation, OpenPhilanthropy, Google Research Scholar Award, Alexander von Humboldt Foundation, and other international funding agencies.
research team also included Ms. Mara Schilling-Wilhelmi and Mr. Martiño Ríos-García from FSU Jena; Mr. Pranav Khetarpal, and Mr. Hargun Singh Grover from IIT Delhi.
Research Contacts: Prof. N. M. Anoop Krishnan: krishnan@iitd.ac.in, Prof. Kevin Maik Jablonka: mail@kjablonka.com
Other News

स्ट्रोक के बाद बोलने की समस्या के उपचार के लिए आई.आई.टी. दिल्ली, एम्स नई दिल्ली और आई.एच.बी.ए.एस. ने विकसित किया मेलोडिक इंटोनेशन थेरेपी (एम.आई.टी.) का पहला हिंदी संस्करण।
Read More
IIT Delhi, AIIMS New Delhi and IHBAS Develop First Hindi Version of Melodic Intonation Therapy (MIT) for Post-stroke Aphasia
Read More
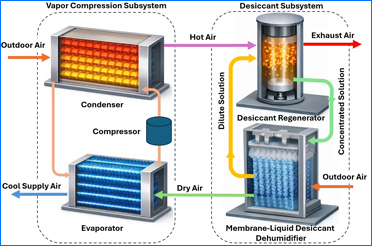
IIT Delhi Researchers Developing a High-Efficiency AC Capable of Reducing Electricity Use by a Third | आई.आई.टी. दिल्ली के शोधार्थी कर रहे हैं बिजली-बचत वाला स्मार्ट एयर कंडीशनर विकसित
Read More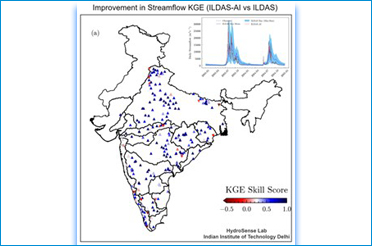
Researchers Develop a Hybrid Physics-AI Framework for National-Scale River Flow Modeling | राष्ट्रीय स्तर पर नदी प्रवाह मॉडलिंग के लिए शोधकर्ताओं ने विकसित किया हाइब्रिड फिजिक्स–AI फ्रेमवर्क
Read More
आई.आई.टी. दिल्ली के शोधकर्ताओं द्वारा मानव वैज्ञानिकों की तरह वास्तविक वैज्ञानिक प्रयोग कर सकने वाले कृत्रिम एजेंट 'AILA' का निर्माण | IIT Delhi Researchers Create AI-Agent ‘AILA’ That Can Conduct Real Scientific Experiments Like Human Scientists
Read More
आई.आई.टी. दिल्ली और एम्स के शोधकर्ताओं ने किया एक निगलने योग्य सूक्ष्म उपकरण विकसित | IIT Delhi and AIIMS Researchers Develop a Swallowable Microdevice That Can Collect Microbial Samples from the Small Intestine
Read More
आईआईटी दिल्ली अध्ययन: एंड्रॉइड ऐप्स से निजी जानकारी उजागर होने का खतरा | Mobile Apps on Android Devices Requiring Precise Location Permissions Can Reveal a Significant Amount of Private Information About Users: Shows IIT Delhi Study
Read More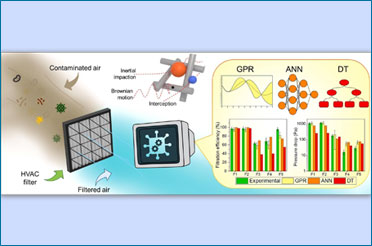
स्वच्छ इनडोर हवा के लिए आईआईटी दिल्ली का स्मार्ट एचवीएसी समाधान | IIT Delhi Researcher-led Team Develops Machine Learning Framework to Design Smarter HVAC Filters to Ensure Healthier Indoor Air Quality
Read More
आई.आई.टी. दिल्ली के शोधार्थियों ने सीमेंट की त्वरित गुणवत्ता जांच के लिए किया एआई मॉडल विकसित | IIT Delhi Researchers Develop AI Models for Instantaneous Quality Check of Cement
Read More
आई.आई.टी. दिल्ली के शोधार्थियों ने डेनिम अपशिष्ट को उच्च गुणवत्ता बनाए रखते हुए बुने हुए कपड़ों में पुनर्चक्रण की विधि की विकसित | IIT Delhi Researchers Develop Method to Recycle Denim Waste to Knitted Garments Without Compromising Quality
Read More
आई.आई.टी. दिल्ली के शोधकर्ताओं ने किया मच्छर रोधी डिटर्जेंट विकसित | Researchers at IIT Delhi developed Mosquito-repellent Detergents
Read More
Artificial Intelligence Transforming Meteorological Prediction Through Innovative Approaches, IIT Delhi Study Shows
Read More
Breakthrough at IIT Delhi: A Multifunctional Optoelectronic Computing Device (MOD-PC) for Next-Gen Neuromorphic Hardware
Read More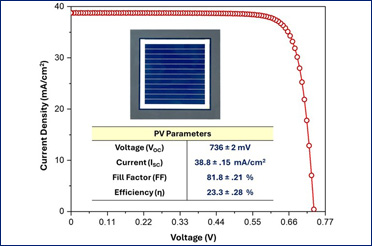
IIT Delhi Researchers Develop High-Efficiency Silicon Heterojunction (SHJ) Solar Cells with Power Conversion Efficiency of >23%
Read More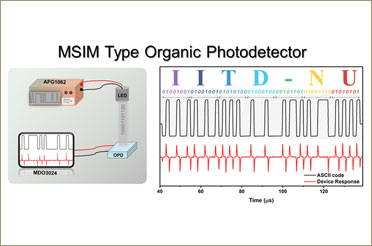
IIT Delhi Researchers Develop High-Speed, Self-Powered Photodetector for Next-Gen Optical Communication
Read More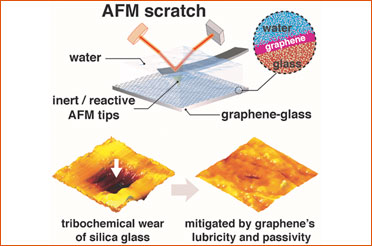
Atomically thin graphene coating effectively protects glasses from simultaneous mechanical and chemical damage under water: Study
Read More
Sprayable Hydrogel by IIT Delhi Researchers for Improving Wound Healing Exhibits Promising Results in Pre-Clinical Trial
Read More